Try Salesforce Starter Suite for free.
Unite marketing, sales, and service in a single app. Try Salesforce Starter Suite today. There's nothing to install. No credit card required.
Unite marketing, sales, and service in a single app. Try Salesforce Starter Suite today. There's nothing to install. No credit card required.


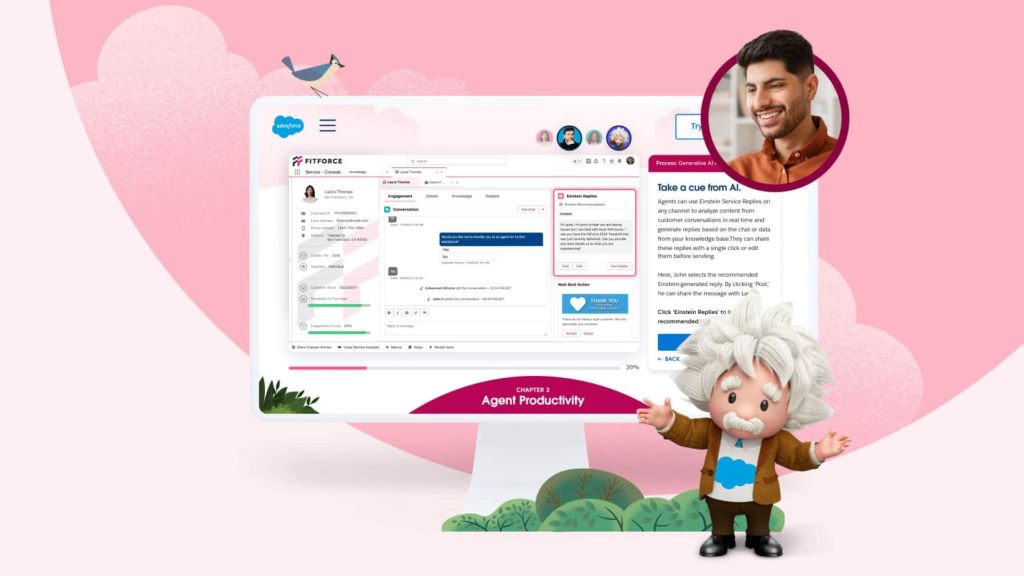
Learn how Salesforce CRM, powered by the trusted Einstein 1 platform, helps everyone at your company be more productive and grow customer loyalty.
Whatever your industry, we offer solutions to modernize your business, save time, and lower costs.
Learn all about CRM, how it can unify all your teams, and how it drives growth and productivity across your business.

Discover how Pro Suite brings marketing, sales, and service tools together.

Browse our AppExchange marketplace, with thousands of customized apps and specialized consulting partners to help any sized business craft a perfectly tailored Customer 360 solution.
Try Salesforce for free. No credit card required, no software to install.
Tell us a bit more so the right person can reach out faster.
Get the latest research, industry insights, and product news delivered straight to your inbox.